A study about the effect of a religion blasphemy issue and heavily biased news to regional election in Jakarta, using Latent Dirichlet Allocation (LDA), Structural Topic Models (STM), and naive bayes.
Author: Nurvirta Monarizqa. This is a final project for Text as Data Course, Center of Data Science, New York University, Spring 2017
Introduction
Although “Unity in Diversity” (Bhinneka Tunggal Ika) is the official motto of Indonesia, apparently, this did not hold well in the case of Jakarta’s Regional Election 2017. Let me introduce Basuki Tjahaja Purnama, known as Ahok, an incumbent seeking re-election. Ahok is Chinese in ethnicity, Christian, disciplined, and very blunt. He is a minority, considering the vast amount of Muslim, Malay / Javanese, and more subtle people of Indonesia. He began as a Vice Governor of Jakarta in 2012 and then became as Governor after Jokowi, the then-Governor was elected as a President in 2014. He has been changing Jakarta in a very good way and bringing lots of improvement. His public acceptance has always been positive.
However, some extremist Islamic organizations began to shake public opinion by citing a Quran verse, Al-Maidah:51 –
“O you who have believed, do not take the Jews and the Christians as allies. They are [in fact] allies of one another. And whoever is an ally to them among you - then indeed, he is [one] of them. Indeed, Allah guides not the wrongdoing people”
– that indirectly suggests that Muslim residents should not vote for Ahok because of his religion. Ahok then suggested people should not to be deceived by the verse. This statement blew up and was considered a blasphemy.
After that incident, news about the election was overshadowed by the blasphemy issue. Fake news were growing as well as intolerance among people. Religious issues seemed to matter more than campaign promises. This paper will discuss how people’s opinions changed over time, before and after the blasphemy controversy.
Hypothesis
People opinions after the incident happened will be significantly different from people opinions before the incident. Also, people opinions will be more polarized.
Background and Literature Review
Ahok Incident and the Timeline
On September 27, 2016, Ahok, in his visitation to Kepulauan Seribu, talked about the ongoing election and cited Al-Maidah:51. The Governor Office then uploaded the meeting video a day after. Not until Buni Yani, an ex-journalist, uploaded the clip from the video to Facebook on October 6, 2016, Ahok’s statement about Al-Maidah:51 went viral. Buni Yani captioned the clip, “Religion Blasphemy.” On that same day, some community organizations reported Ahok to the Police with the accusation of religion blasphemy.
People opinions were heated after that. Five days after the report on October 11, 2016, Indonesian Islamic Scholars Association, known as MUI, produced a “fatwa” that indeed, Ahok did commit blasphemy and insulted the Quran. On November 4, 2016, hundred thousands of people participated in a rally called “411 rally / defending Islam rally”, demanding that Ahok be prosecuted. On November 12, 2016, Ahok was charged for religion blasphemy. The first trial was held on December 13, 2016. (CNN Indonesia, 2017)
Heavily Polarized Media in Indonesia
Since 2014, the number of provocative media outlets in Indonesia has been growing. Three of the most notable websites are www.portal-islam.id, www.seword.com, and www.beritanews.com. Portal-Islam is a re-birth of a previously infamous website, www.pkspiyungan.org (therefore, in this paper, Portal-Islam will be referred as “Piyungan”), that was blocked by the government (Tribun News, 2017) due to the amount of fake and extremely biased news. People behind the website belongs to radical Islamic organizations that are heavily opposed to non-Muslim leaders. Thus, we will use Piyungan as anchor negative.
Seword and Beritanews (we will refer the combination of both as “Seword” in this paper) are the opposite; they claimed themselves as a more-liberal news and spread tolerance, but in fact, they are also extremely opinioned and tend to attack other candidates (Okezone, 2017) and their supporters. However, since there is no specific user-aggregated website dedicated to support Ahok in general, we will use Seword as an anchor positive.
Prior Research/Related works
Since this is an ongoing issue, there is no formal publication in social science discussing Ahok controversy yet. However, Yuli Ismartono in February 2017 gave speech in Columbia University titled “Debunking the Rumors on Jakarta’s Election.” This lecture discussed the role of media and fake/controversial news on the election. (Ismartono, 2017)
Text classification and sentiment analysis on some provocative media sources in Bahasa Indonesia has been done by Rasywir and Purwarianti in 2015 using Naïve Bayes with 91.36% accuracy. (Errissya Rasywir, 2015)
Data Sources and Methodology
To collect data on popular opinions, we initially wanted to use Twitter. However, Twitter does not provide historical tweets, so it is impossible to get tweets beyond one week from the time we started the research in early April. Therefore, we used four different independent user-aggregated news sources, websites that allow people to express their opinions through articles. Three of them were mentioned in the literature review section as the anchors: portal-islam.com (“Piyungan”), seword.com, and beritanews.com (“Seword” group). Another source is Kompasiana.com, a more neutral source.
Data collection was done using BeautifoulSoup package in python to scrap the content of the websites between June 30, 2016, and December 20, 2016. We successfully obtained 874 articles in seword.com, 777 articles in beritanews.com, 4,956 articles in portal-islam.id, and 8,292 articles in Kompasiana. Seword groups have much lower number of articles because they are relatively newer compared to Kompasiana and Piyungan.
Text preprocessing was done in R using quanteda package to create corpus and document term matrix. We removed stopwords using Bahasa stopwords list (Tala, 2003), remove punctuation but did not stem the words as in Bahasa, stemming could heavily affect the sentiment. Additionally, we applied three types of analysis here: exploratory, unsupervised, and supervised learning.
Exploratory
For the exploratory phase, we used the bursty model in R to detect interesting structure in the documents and allow us to see which words have dramatic shifts in usage over time (Kleinberg, 2002). That could help us to explore the data and get some initial insight.
Unsupervised learning
We used Latent Dirichlet Allocation (LDA) and Structural Topic Models (STM) packages in R to extract the topics for each document.
Supervised learning
With supervised learning, we want to know how people in Kompasiana express their opinions regarding the selected issues, using Seword and Piyungan as the extreme anchors. Since there is a limited source in R to capture emotions or sentiments in Bahasa Indonesia, we use the topics from unsupervised learning to filter the topics we are interested in (election and tolerance issues). We give the respected article a binary value, 1 or -1, with one is for Seword articles and -1 is for Piyungan articles in selected provocative topics. We tagged them based on the source because we knew that both sources are directly opposite to each other.
We trained the Naïve Bayes model on extreme anchors, then classified the opinions on Kompasiana using trained model.
Hypothesis test
We binned posterior probabilities from supervised learning in a weekly bin. Then we will compare the distribution of posterior probabilities between ten weeks before the incident and ten weeks after using Kolmogorov–Smirnov test with confidence interval of 95%.
Result and Discussion
Data Exploration
Using burst technique in R, we wanted to know how bursty some words are. If a particular word is trending during a short amount of time, that was perceived as a burst. Table 1 shows the burstiness of words “Al-Maidah” (the verse), “blasphemy,” “religion,” “Chinese,” and “Ahok.” The red lines indicate the time when the incident happened (September 27, 2016).
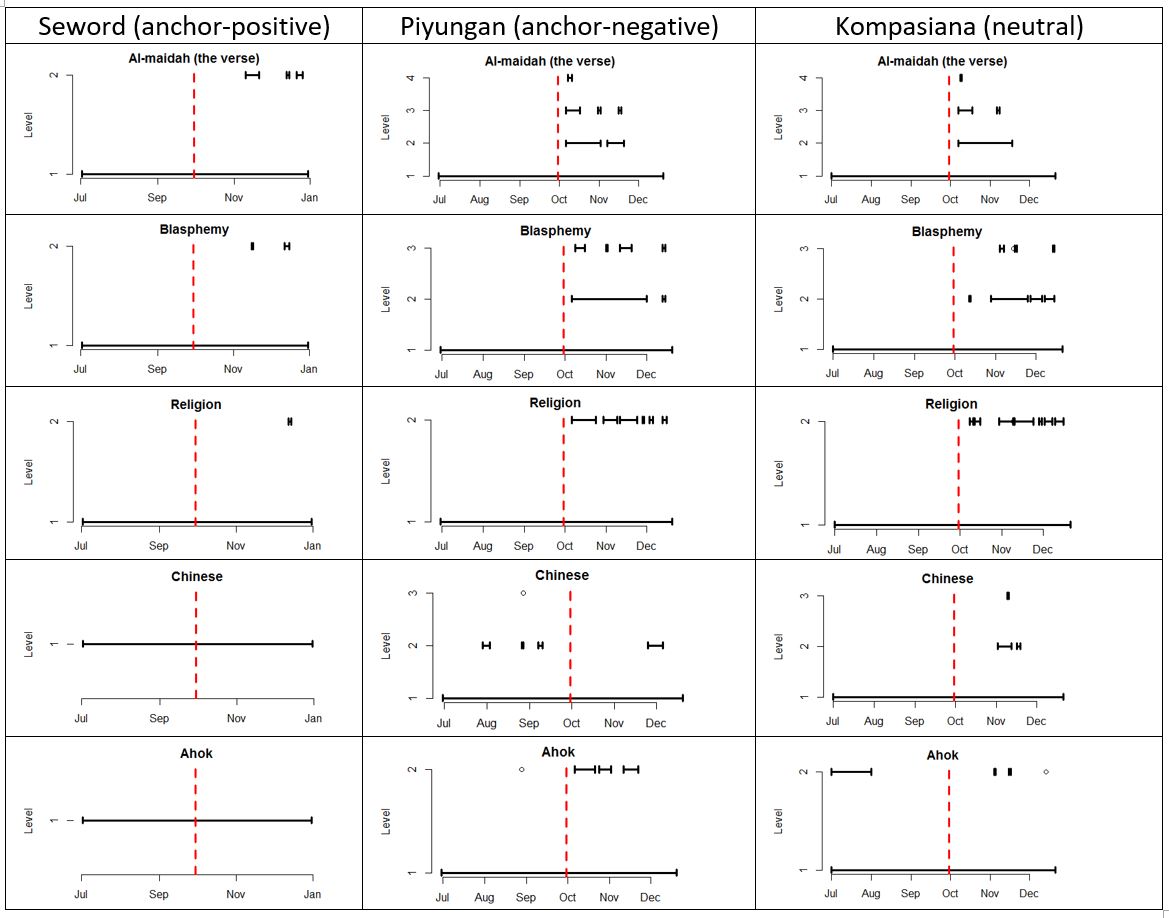
Table 1. Burstiness of some kewyords
“Al-maidah,” “blasphemy,” and “religion” burst in three different sources after the incident happened. However, “Chinese” and “Ahok did not burst in the Seword group. That because Ahok was frequently mentioned by Seword from the start, so distribution of that word across time is just the same. Interestingly, in Piyungan, prior the incident, word “Chinese,” when referring to ethnicity, burst, while “religion” did not. Religion just burst after the incident happened, indicating that Piyungan addressed ethnicity issues more than religious ones before the incident happened, then switch after the incident went viral.
Topic Models
Burstiness helps identifying which words are trending, but topic models can identify the correlation of words and extract the topics that are dominant for each document. For the first iteration, we used LDA from the lda package to get top five topics. We named those topics “Party discussion” (pre-election discussion among parties to select candidates), “Election in general” (campaigns, candidates, debate, the promises), “411 rally”, “The blasphemy,” and “Blasphemy trial.” Figure 1 shows topic coverage for each source. The more red, the more that topic was being discussed in the source.
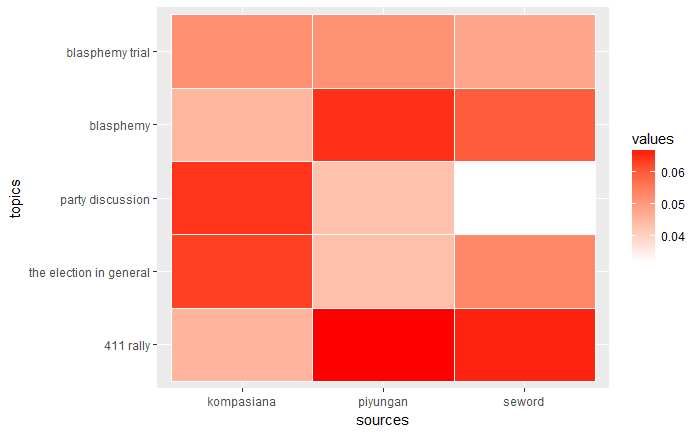
Figure 1. Topics coverage across sources
As we can see from Figure 1, Piyungan was interested in the 411 rally and also the blasphemy issue, while interestingly, the Seword group also cover the 411 rally a lot, but did not truly cover the party discussion. Meanwhile, Kompasiana did not share the same pattern with both anchors. Kompasiana discuss the election in general and pre-election party discussion more than blasphemy-related issues such as 411 rally and blasphemy trial. Figure 2 shows how the distribution varies not only across the source but also the time.
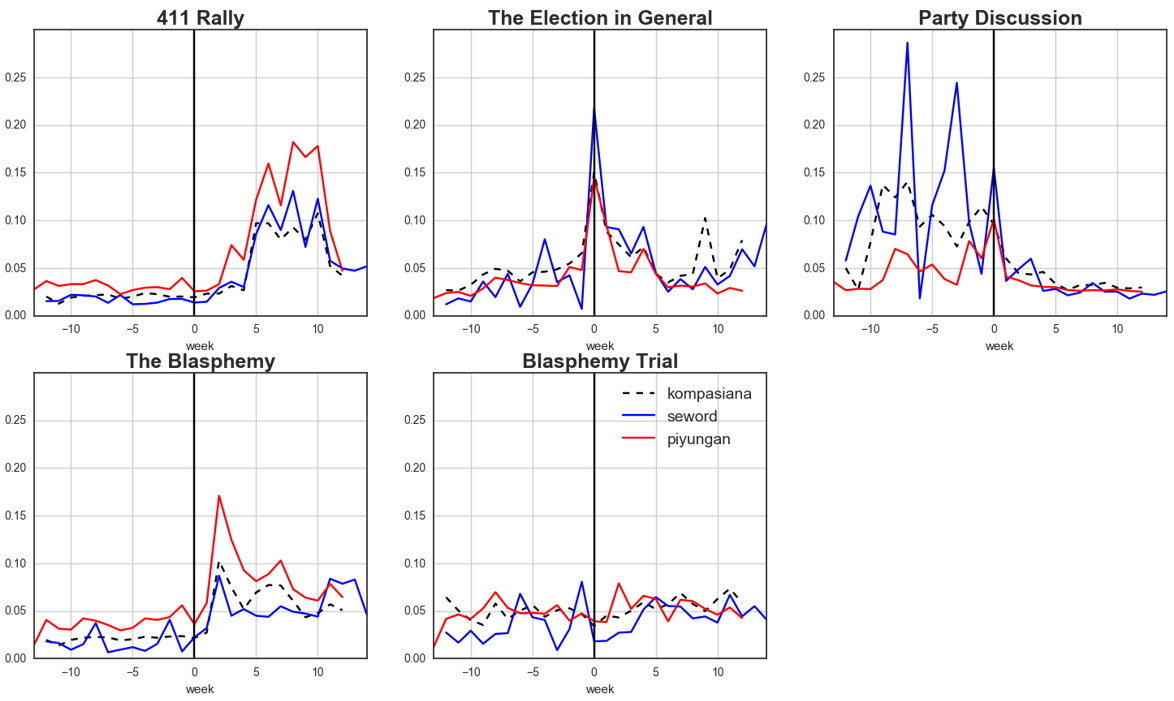
Figure 2. Topics distribution across time
During the incident week, there is a peak in the election topic but not in the blasphemy topic. That happened because on September 30, three days after incident happened, the election committee announced the candidates for the election. However, we can see that the trend diminished over time, while 411 rally and the blasphemy took over the media coverage.
LDA assumes that every topic is not correlated with each other, while in reality, they do correlate as is the case with the 411 rally and the blasphemy. Therefore, we use the stm package in R to allow the relationship and run the topic model only on Piyungan and Seword. Here we used 40 as the number of topics and “Gibbs” as the calculating method. Figure 3 shows the result. The number one topic with the highest number of topic proportions is Topic 37, the blasphemy, with “ahok” (Ahok), “penistaan” (blasphemy), and “agama” (religion) being the keywords.

Figure 3. Forty topics of STM
From these forty discovered topics from STM, we then created a new corpus that consists only of the documents associated with tolerance-related topics (the blasphemy, protest rally, tolerance, Al-Maidah, MUI’s fatwa, Ahok trial, China) and used this newly created corpus as anchor documents for supervised learning.
Naive Bayes and Hypothesis tested
Before we applied the naïve bayes model to the kompasiana corpus, we first trained the model on the 1,304 documents from previous step (consists of only tolerance-related issues). With an 80% training set and a 20% test set, we get 88% accuracy, 60% recall and 82% precision after ten times cross validation. Then, we applied the trained model to the Kompasiana corpus to get the prior probabilities of each documents, to determine whether it was more similar to Seword (bias toward Ahok) or Piyungan (anti-Ahok). We binned the result in a weekly bin, calculated the differences between two posterior probabilities for each document, and plotted the kernel density estimator (KDE) of the posterior differences for ten weeks before the incident, during the incident week, and ten weeks after the incident.
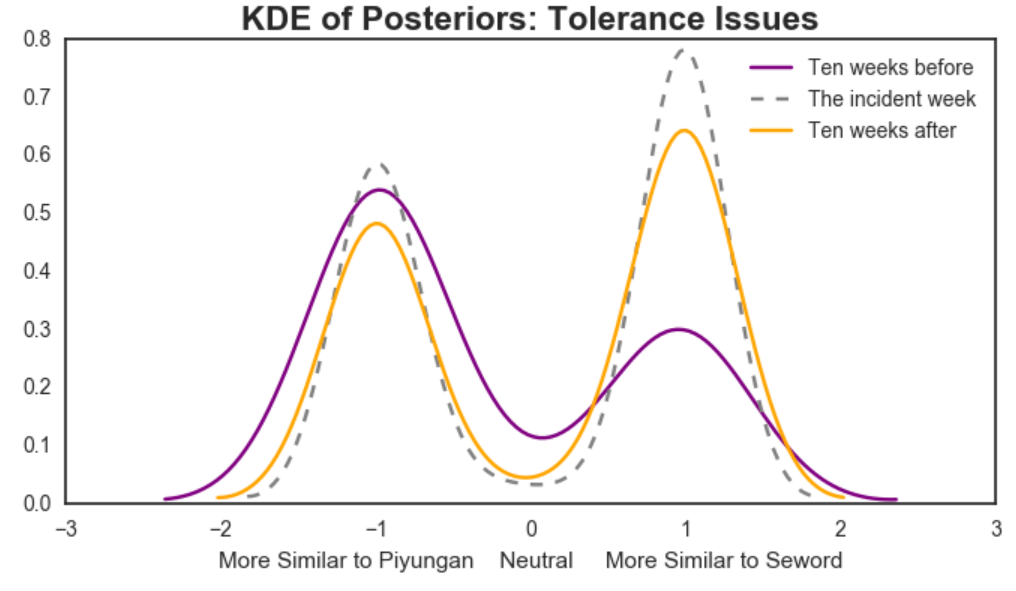
Figure 4. KDE of Posterior Probabilities. -1: similar to Piyungan, 1: similar to Seword
As we can see in Figure 4, there were notable changes on the people’s opinions in Kompasiana before, during, and after the incident happened. Ten weeks before the incident, people were less polarized, although there are more people discussed the same topics as Piyungan, such as the party discussions, before the incident. the KDE values are less than 0.6 for both peaks. When the incident happened (September 30 – October 6), we can see that the KDE value is increasing steeply for “1” group (similar to Seword) from less than 0.3 to 0.8, and small increase for “-1” group. This indicates that people were really polarized when the incident happened. Ten weeks after, people were more calmed down, as the KDE values were not as high as the ones during the incident, but still arguably higher than ten weeks before the incident for the “1” side. As the KDE value for “0” or neutral side was the highest in ten weeks before incident, we can say that indeed, people in Kompasiana became more polarized.
To quantify the differences of each distribution and test whether they are statistically significant, we applied Kolmogorov-Smirnov (KS) two-tail test. This tests whether 2 samples are drawn from the same distribution, so if the p-value is smaller than 0.05, we reject the null hypothesis and that means, the two distributions tested are statistically different.
| Pair | p-value | Result |
|---|---|---|
| Ten weeks prior vs incident week | 0.006867 | Reject |
| incident week vs ten weeks after | 0.999593 | Do not reject |
| Ten weeks prior vs ten weeks after | 0.007164 | Reject |
Table 2. KS-test results
From Table 2, we can infer that people’s opinions on tolerance-related issues during ten weeks prior incident and ten weeks after the incident are significantly different. However, there is no statistically difference between people’s opinion during the incident week and ten weeks after the incident.
Conclusions
People opinions in Indonesia were really polarized during the Ahok’s controversy week. The change between ten weeks before and ten weeks after the incident is statistically significant. However, this does not necessary conclude that people become more tolerant or more intolerant. To do so, further research is needed.
References
- CNN Indonesia. (2017, May 9). www.cnnindonesia.com. http://www.cnnindonesia.com/nasional/20170509062010-15-213306/kronologi-kasus-ahok-dari-penodaan-ke-pernyataan-permusuhan/
- Errissya Rasywir, A. P. (2015). Eksperimen pada Sistem Klasifikasi Berita Hoax Berbahasa Indonesia Berbasis Pembelajaran Mesin. Cybermatika.
- Ismartono, Y. (2017). Debunking the Rumors on Jakarta’s Election. Jakarta.
- Kleinberg, J. (2002). Bursty and Hierarchical Structure in Streams. The 8th ACM SIGKDD International Conference on Knowledge.
- Okezone. (2017, February 21). okezone.com. http://news.okezone.com/read/2017/02/21/337/1624667/tulis-hoax-situs-seword-com-terancam-kena-uu-ite
- Tala, F. (2003). A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia. Amsterdam: Universiteti van Amsterdam The Netherlands.
- Tribun News. (2017, January 5). tribunnews.com. http://www.tribunnews.com/kominfo/2017/01/05/informasi-hoax-ancam-indonesia-11-situs-ini-diblokir-pemerintah